Spring AI 应用 - 智能记者 参考实现: https://github.com/mshumer/ai-journalist 上面是通过 Claude 配合 SERP 搜索 API,使用 Python 语言实现的,本文通过 GitHub Copilot 辅助改为了基于 Spring AI 的 Java 版本,由于我个人没有开通 Claude,所以使用的 OpenAI。 AIJournalist 实现基本定义如下: 1234567 2024-06-26 系列文章 > SpringAI #SpringAI
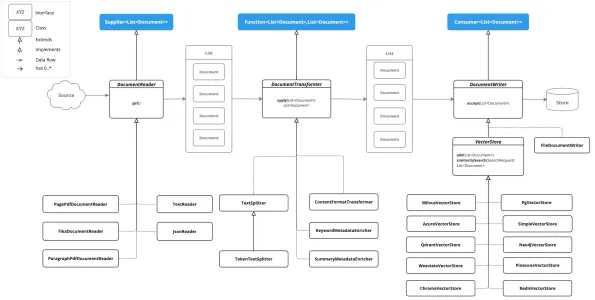
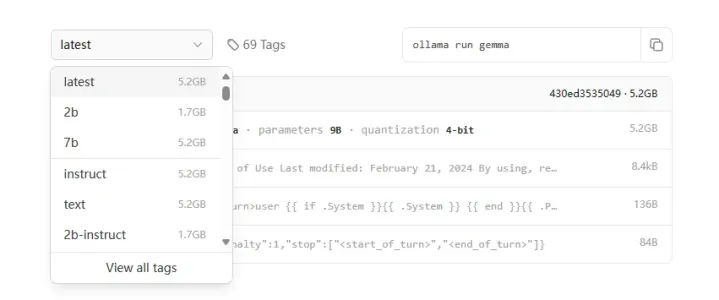
Spring AI ETL 流水线 先纠正 Spring AI 使用本地 Ollama Embeddings 中的一个错误,当启动 Ollama 之后,Windows会有托盘图标,此时已经启动了 Ollama 的服务,访问 Embedding 时不需要运行 ollama run gemma ,只有访问 chat 时才需要启动一个大模型。 Spring AI 提供的 ETL 流水线比较全面,使用很简单。提取、转换和加载 (ET 2024-06-26 系列文章 > SpringAI #SpringAI #ETL
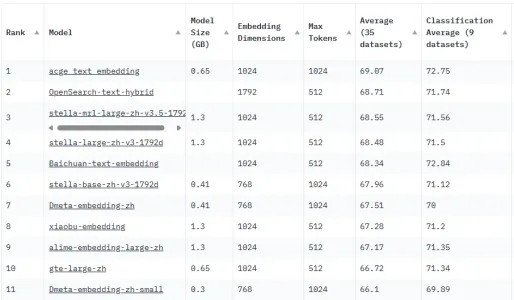
Ollama 导入自定义模型 在前面 Spring AI 使用本地 Ollama Embeddings 中查找 Embedding 模型的时候,首先看到了 mofanke/dmeta-embedding-zh 模型,这才发现 Ollama 中除了官方模型外还有用户自己上传的其他模型,搜索 dmeta-embedding-zh 找到了抱脸网上的对应模型: https://huggingface.co/DMetaSoul 2024-06-26 系列文章 > SpringAI #SpringAI #Embeddings #Ollama
Spring AI 使用本地 Ollama Embeddings 使用 OpenAI 的 Embeddings 接口是有费用的,如果想对大量文档进行测试,使用本地部署的 Embeddings 就能省去大量的费用,所以我们尝试使用本地的 Ollama Embeddings。 首先本地安装 Ollama: https://ollama.com/download 即使你电脑没有性能很强的显卡,仅仅依靠 CPU 也能运行一些参数量较小的模型。ollama 中下载量最多的 2024-06-26 系列文章 > SpringAI #SpringAI #Embeddings #Ollama
Spring AI 连续对话 在前面 Spring AI Chat 简单示例 中我们只调用了一次请求,返回了一个结果,我们见过的各种 chat 都是支持连续对话的,AI 需要记住我们的上下文才能让对话连贯起来,通过 API 调用的时候每次对话都是一次无状态的独立请求,想要实现连续对话就需要我们自己记住对话的历史,在每次调用 API 的时候将对话历史传递给 API。 本文就简单实现连续对话,并且引申一些相关的扩折或者优化。 2024-06-26 系列文章 > SpringAI #SpringAI
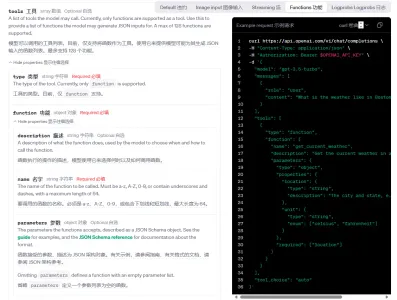
Spring AI Function 的实现原理? 在前面 Spring AI Chat 简单示例 中介绍了 Chat 中的 Function 用法,我很好奇这个 Function 是如何被调用的,就在下面代码中加了断点看执行: 执行过程中进入了这个方法,并且符合 Request 类型的参数,这是如何实现的?就像魔法一样神奇,这是 Spring AI 的功能还是 OpenAI 的功能?好奇心引导我必须深入看看。 跟踪代码 - 加日志先找了几个断点 2024-06-26 系列文章 > SpringAI #AI #SpringAI #Function
Spring AI Embeddings 和 Vector 入门 在前面 Spring AI Chat 简单示例 中介绍了 Chat 的基本用法,本文在此基础(主要是pom.xml)上继续探索 Embedding 和 Vector。 官方文档: embeddings: https://docs.spring.io/spring-ai/reference/api/embeddings/openai-embeddings.html redis: https:// 2024-06-26 系列文章 > SpringAI #AI #SpringAI #Embeddings #Vector
Spring AI Chat 简单示例 官方文档地址: https://docs.spring.io/spring-ai/reference/index.html Spring AI 可以方便 Java 开发者在代码中集成 AI 的功能,通过 Spring 提供的抽象,可以方便的切换不同的AI提供商,Spring AI 是对 AI 的使用,并不涉及 AI 的训练。 特别注意: Spring AI 目前还很不稳定,官方文档还有大量错误, 2024-06-26 系列文章 > SpringAI #AI #SpringAI
我做了个Hexo博客 最近花了两个周末的时间边学变做Hexo博客,最终成品地址如下: https://blog.mybatis.io 下面先说说做博客的经过,想做Hexo博客一开始是因为看到了 hexo-theme-icarus 主题,这个主题样式如下: 首页 内容页 这个主题是不是真的好看?我总觉得我喜欢这个主题是因为和CSDN的样式很像,支持一栏、二栏、三栏,和CSDN确实很像: 我用Hexo做独立博客 2024-06-23 技术文章 > Hexo
(八)扩展yGuard实现签名 前面铺垫了这么多,终于开始实现签名反篡改的功能了。 下载 yGuard 源码(https://github.com/yWorks/yGuard), 然后先修改一处错误,在 settings.gradle 中定义的项目名是错的(和github上的名字不一样,git clone 下载会使用 github 定义的名字yGuard,估计作者本地建的项目名是 yguard),将里面的 rootProject 2024-06-22 系列文章 > 混淆技术研究笔记 #混淆 #yGuard #签名
(七)Ant扩展介绍 ant 扩展官方文档:https://ant.apache.org/manual/develop.html Writing Your Own Task编写你自己的任务 1. 创建一个XXTask类创建一个Java类继承org.apache.tools.ant.Task ,实际上不继承也可以,定义一个 execute() 方法就可以,例如下面的例子: 12345public class MyTa 2024-06-22 系列文章 > 混淆技术研究笔记 #混淆 #yGuard #Ant
(六)如何基于yGuard实现? 确定参考 <adjust> 作为入口后,就需要详细了解这部分代码的逻辑。 需要看yguard源码了,你会如何阅读一个完全不了解的源码? 我通常的策略都是找一个目标,添加代码依赖,写好demo,debug跟踪代码看。如果漫无目的的看,很难串起来整个流程,范围太大也容易迷失。 先在配置中增加 <adjust> 配置: 123<adjust replacePathPolic 2024-06-22 系列文章 > 混淆技术研究笔记 #混淆 #yGuard
(五)混淆后如何反篡改? 有了上一节的基础工具后,接下来要考虑如何反篡改。 本文采用的是对混淆后的代码,针对某些关键包的字节码数据计算md5值,对所有类计算完成后对md5值进行排序,排序后拼接字符串再次计算md5值,最后通过私钥对md5进行RSA对称加密,加密后的内容要放到核心的jar包中。 程序在启动时,需要有一些入口点调用代码校验,代码校验时使用classloader搜索指定包中的所有class数据,对这些数据按照相同 2024-06-22 系列文章 > 混淆技术研究笔记 #混淆 #yGuard #反篡改
(四)反篡改介绍 先来看看AI的介绍,为了防止Java代码打包的JAR包被篡改,可以采取以下几种措施: 使用数字签名:可以使用Java的签名工具(如Jarsigner)对JAR包进行数字签名。签名可以确保JAR包的完整性和来源可信性。在验证JAR包时,可以使用Java的验证工具(如Jarsigner或Java Web Start)来验证签名。 使用加密技术:可以使用加密算法对JAR包进行加密,确保只有授权的用户 2024-06-22 系列文章 > 混淆技术研究笔记 #混淆 #yGuard #反篡改
(三)多模块混淆 示例项目: https://github.com/abel533/yguard-modules-parent 假设有如下多模块项目: 1234module-parent├─module-a├─module-b└─module-c 在 混淆技术研究笔记(一)常见工具介绍 中提到,默认只能使用单模块混淆,每个模块构建时的上下文只有自己,无法对其他模块进行处理,虽然 <<inoutpa 2024-06-22 系列文章 > 混淆技术研究笔记 #混淆 #yGuard
(二)yGuard入门 yGuard官方文档地址:https://yworks.github.io/yGuard/index.html yGuard官方文档包含了比较全面的内容,由于文档是英文的,而且文档翻译后的浏览效果不是特别好,所以看文档入门有点难度。 这个系列的重点是混淆,所以不会涉及yGuard中的shrink用法,主要是rename的用法。 本文使用的 maven-antrun-plugin 插件,插件的基本配 2024-06-22 系列文章 > 混淆技术研究笔记 #混淆 #yGuard
(一)常见工具介绍 混淆技术研究笔记包含多篇内容,记录了一次混淆的研究和应用的过程。 最近有一个 Java 的底层框架需要进行混淆(从原始的 Java 项目改造为了 Maven 多模块),而且要实现和该框架以前一样的混淆和反篡改功能(旧的打包配置我没权限看到),为了实现这些功能,开始了本系列的研究。 1. 常见工具介绍第一节先来点简单的内容,下面是通过 AI 生成的几款常见的混淆工具简介及对比。 ProGuard 2024-06-22 系列文章 > 混淆技术研究笔记 #混淆 #yGuard
避免啰嗦,不要多此一举! 看到一段代码,写的比较啰嗦就用GitHub Copilot简化了一下,简化结果很简单,复杂度从273%降低到13%(复杂度使用IDEA插件 Better Highlights )。代码行数从79行变成了29行,下面是原始代码: 1234567891011121314151617181920212223private static boolean comparelogic(String condit 2024-06-06 技术文章 > 编程技巧 #Java #设计模式 #策略模式 #代码优化
Redis 异常三连环 本文针对一种特殊情况下的Reids连环异常,分别是下面三种异常: NullPointerException: Cannot read the array length because “arg” is null JedisDataException: ERR Protocol error: invalid bulk length JedisConnectionException: Unex 2024-06-04 技术文章 > 解决问题 #异常 #Redis #Java
谷歌 Colab:学习 Python 和大模型的利器 简介谷歌 Colab,又称 Colaboratory,是一个基于 Jupyter 笔记本的免费在线平台,可让您在浏览器中编写和执行 Python 代码。它无需配置,即可轻松访问 GPU 和 TPU 等强大硬件,并支持丰富的文本、代码、图像、视频等格式,非常适合学习 Python 和大模型。 网址:https://colab.research.google.com/ 谷歌colab更简洁,打开 2024-03-18 技术文章 > 工具